Genestack Alerting
Genestack is made up of a vast array of components working away to provide a Kubernetes and OpenStack cloud infrastructure to serve our needs. Here we'll discuss in a bit more detail about how we configure and make use of our alerting mechanisms to maintain the health of our systems.
Overview
In this document we'll dive a bit deeper into the alerting components and how they're configured and used to maintain the health of our genestack. Please take a look at the Monitoring Information Doc for more information regarding how the metrics and stats are collected in order to make use of our alerting mechanisms.
Prometheus Alerting
As noted in the Monitoring Information Doc we make heavy use of Prometheus and within the Genestack workflow specifically we deploy the kube-prometheus-stack which handles deployment of the Prometheus servers, operators, alertmanager and various other components. Genestack uses Prometheus for metrics and stats collection and overall monitoring of its systems that are described in the Monitoring Information Doc. With the metrics and stats collected we can now use Prometheus to generate alerts based on those metrics and stats using the Prometheus Alerting Rules. The Prometheus alerting rules allows us to define conditions we want to escalate using the Prometheus expression language which can be visualized and sent to an external notification systems for further action.
A simple example of an alerting rule would be this RabbitQueueSizeTooLarge
RabbitQueueSizeTooLarge Alerting Rule Example
``` yaml
rabbitmq-alerts:
groups:
- name: Prometheus Alerts
rules:
- alert: RabbitQueueSizeTooLarge
expr: rabbitmq_queuesTotal>25
for: 5m
labels:
severity: critical
annotations:
summary: "Rabbit queue size too large (instance {{ `{{ $labels.instance }}` }} )"
```
In Genestack we have separated the alerting rules config out from the primary helm configuration using the additionalPrometheusRulesMap directive to make it a bit easier to maintain.
Doing it this way allows for easier review of new rules, better maintainability, easier updates of the stack and helps with portability for larger deployments. Keeping our configurations separated and checked in to the repo in such a manner is ideal for these reasons.
The alternative is to create the rules within your observability platform, in Genestack's default workflow this would be Grafana. Although the end user is free to make such a choice you end up losing a lot of the benefits we just mentioned while creating additional headaches when deploying to new clusters or even during basic updates.
You can view the rest of the default alerting rule configurations in the Genestack repo alerting rules yaml file.
To deploy any new rules you would simply run the Prometheus Deployment and Helm/Prometheus will take care of updating the configurations from there.
Alert Manager
The kube-prometheus-stack not only contains our monitoring components such as Prometheus and related CRD's, but it also contains another important features, the Alert Manager. The Alert Manager is a crucial component in the alerting pipeline as it takes care of grouping, deduplicating and even routing the alerts to the correct receiver integrations. Prometheus is responsible for generating the alerts based on the Alerting Rules we defined. Prometheus then sends these alerts to the Alert Manager for further processing.
The below diagram gives a better idea of how the Alert Manager works with Prometheus as a whole.
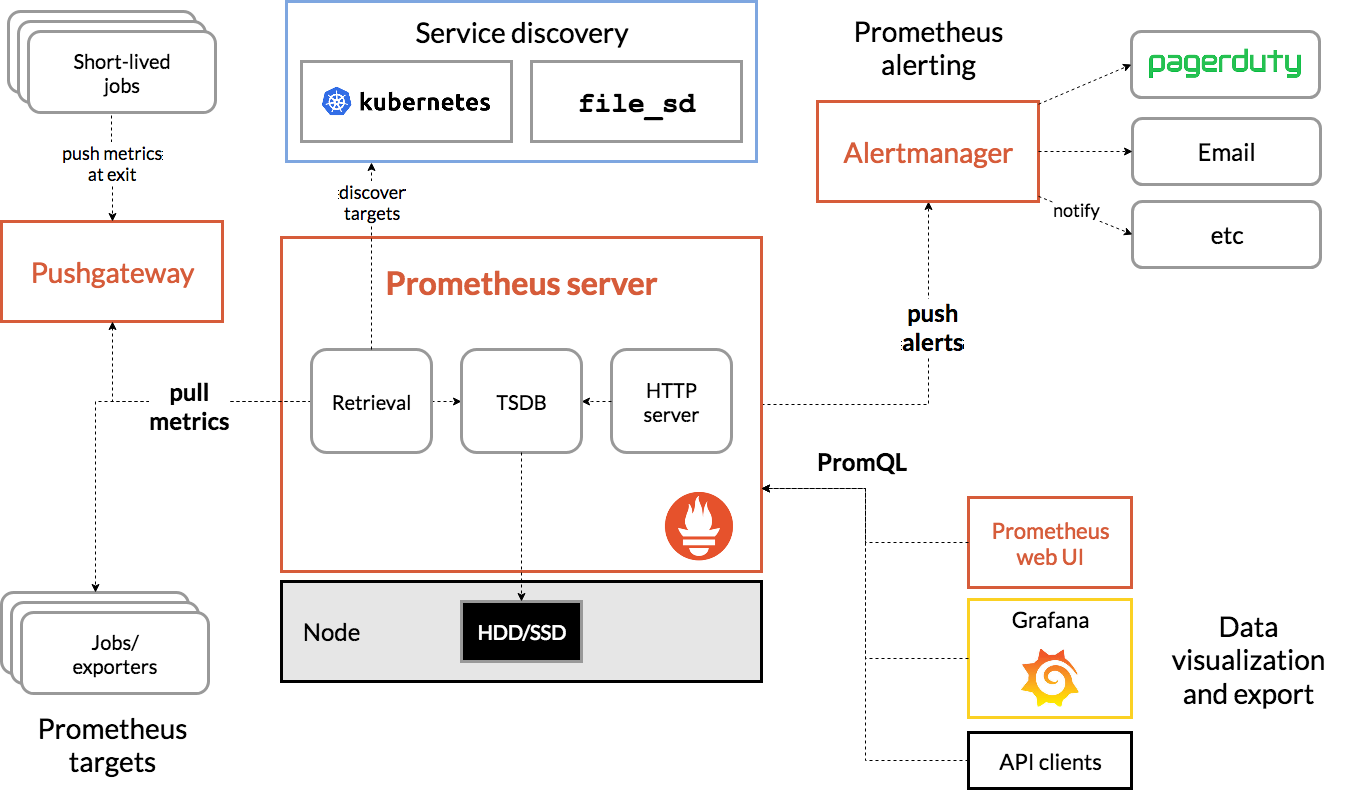
Genestack provides a basic alertmanager_config that's separated out from the primary Prometheus configurations for similar reasons the alerting rules are. Here we can see the key components of the Alert Manager config that allows us to group and send our alerts to external services for further action.
- Inhibit Rules Inhibition rules allows us to establish dependencies between systems or services so that only the most relevant set of alerts are sent out during an outage
- Routes Routing-related settings allow configuring how alerts are routed, aggregated, throttled, and muted based on time.
- Receivers Receiver settings allow configuring notification destinations for our alerts.
These are all explained in greater detail in the Alert Manager Docs.
The Alert Manager has various baked-in methods to allow those notifications to be sent to services like email, PagerDuty and Microsoft Teams. For a full list and further information view the receiver information documentation.
The following list contains a few examples of these receivers as part of the alertmanager_config found in Genestack.
We can now take all this information and build out an alerting workflow that suits our needs!
Genestack alerts
Genestack supplies default alerts, some of which are configured as part of the prometheus install and some of them come from the exporters deployments directly and are not controlled by Genestack. View the list of currently defined alerts supplied by genestack at Genestack Alerts.